
티스토리 뷰
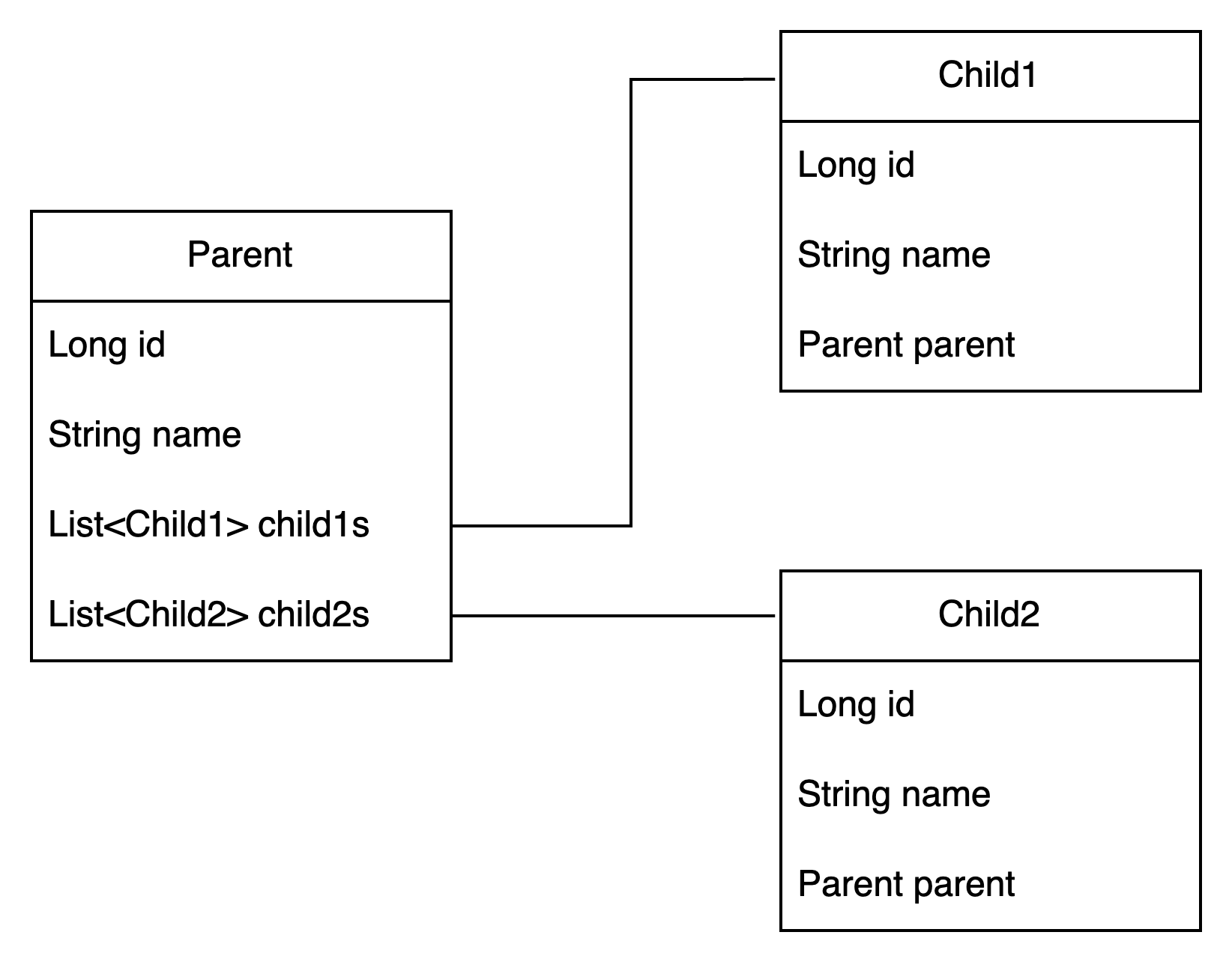
일을 하면서 OneToMany 관계를 여럿 가지는 부모 엔티티를 자식과 함께 가져와야만 하는 경우들을 마주친다.
때로는 비즈니스 제약으로 규모는 크지 않으나 부모 - 자식1 - 자식2 등의 2개 이상의 계층을 한 번에 가져와야 하는 경우도 있다.
왜 hibernate는 단일 쿼리로의 다중 List 초기화를 방지하며,
왜 부모는 자식을 항상 Set이 아닌 List로 초기화할까?
환경: hibernate-core 6.5.3 Final
MultipleBagFetchException
하나의 쿼리에서 둘 이상의 List를 Fetch Join으로 초기화하는 것은 불가하다.
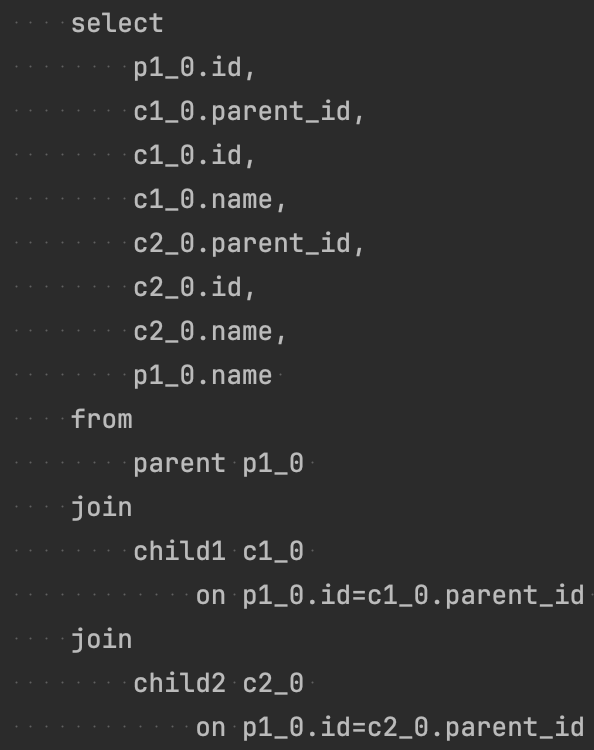
Lazy Loading으로 Parent의 두 Child 컬렉션을 설정해둔 뒤 두 개의 Fetch Join으로 한 번에 연관된 데이터를 가져오려 하면 아래처럼 예외가 발생한다.
TypedQuery<Parent> query = entityManager.createQuery(
"select p from Parent p join fetch p.child1s c1 join fetch p.child2s c2", Parent.class);
try {
Parent findParent = query.getSingleResult();
...

사용자 입장에서는 아래와 같은 쿼리를 예상했겠지만, multiple bags에 대한 조회는 불가능하다는 응답만이 반환된다.
select
...
from
parent p1_0
join
child1 c1_0
on p1_0.id=c1_0.parent_id
join
child2 c2_0
on p1_0.id=c2_0.parent_id
hibernate는 런타임에 List를 PersistentBag라는 프록시로 대체하고 지연 로딩 시 사용 시점에 초기화하는데, Fetch Join을 사용하여 명시적으로 하나의 쿼리에서 초기화를 시도하면 MultipleBagsFetchException이 발생한다.
원인: Cartesian Product를 인스턴스화하는 과정이 지나치게 비싸다
위의 예상되는 쿼리로 두 개의 컬렉션을 한 번에 가져왔다면 hibernate가 처리해야 할 ResultSet을 상상해 보자.
두 개의 컬렉션에 각각 두 개의 자식이 포함된 한 부모를 가정한다.
| parent_id | parent_name | child1_id | child1_name | child2_id | child2_name |
| 1 | parent | 1 | child1_1 | 1 | child2_1 |
| 1 | parent | 1 | child1_1 | 2 | child2_2 |
| 1 | parent | 2 | child1_2 | 1 | child2_1 |
| 1 | parent | 2 | child1_2 | 2 | child2_1 |
두 컬렉션의 크기가 각각 n, m라면, Cartesian Product로 인해 총 n*m개의 row를 가진 Result Set을 가져올 것이고 Hibernate는 이를 인스턴스로 만들어 컬렉션을 채워나가야 한다.
이때 다중 컬렉션 초기화가 컬렉션의 개수에 따라 공간 복잡도가 선형적으로 증가하고, OOM(Out Of Memory) 발생 가능성이 있어서 예외를 발생시킨다 말하면 맞는 설명일까? 만약 데이터의 크기가 크지 않다면 사용자 판단 하에 사용해도 될 듯한데 원천 차단하는 이유는 무엇일까?
여러 개의 Set은 한 번에 초기화해도 MultipleBagsFetchException이 발생하지 않는다.
같은 상황에서 컬렉션의 자료 구조를 Set으로 변경하면 문제없이 원하는 쿼리가 수행된다.
@Entity
public class Parent {
...
@OneToMany(mappedBy = "parent")
private Set<Child1> child1s = new HashSet<>();
// private List<Child1> child1s = new ArrayList<>();
@OneToMany(mappedBy = "parent")
private Set<Child2> child2s = new HashSet<>();
// private List<Child2> child2s = new ArrayList<>();
...
자료 구조만 바꾸었는데 원했던 데이터가 가져와진다는 것은 Result Set의 크기로 인한 OOM이 문제가 아니라는 뜻이다.
자료 구조에 의한 객체 초기화의 시간 복잡도가 원인이다.
위의 예시에서의 Result Set의 자식 인스턴스들이 처리되는 흐름을 고민해 보자.
| parent_id | parent_name | child1_id | child1_name | child2_id | child2_name |
| 1 | parent | 1 | child1_1 | 1 | child2_1 |
| 1 | parent | 1 | child1_1 | 2 | child2_2 |
| 1 | parent | 2 | child1_2 | 1 | child2_1 |
| 1 | parent | 2 | child1_2 | 2 | child2_1 |
- hibernate는 parent_id = 1인 인스턴스에 List 또는 Set을 프록시로 대체한 두 컬렉션을 넣어둔다.
- row 1: child1s 컬렉션에 child1_1이 있는지 확인한다. 없으므로 생성한다.
- row 1: child2s 컬렉션에 child2_1이 있는지 확인한다. 없으므로 생성한다.
- row 2: child1s 컬렉션에 child1_1이 있는지 확인한다. 있으므로 넘어간다.
- row 2: child2s 컬렉션에 child2_2이 있는지 확인한다. 없으므로 생성한다.
- ...
이미 눈치챘겠지만, 컬렉션을 채워 넣는 과정에서 있는지 확인하는 프로세스가 List(PersistentBag)와 Set(PersistentSet) 자료구조의 특성으로 인해 다르다.
List를 사용하는 경우, 두 컬렉션의 크기 곱(n * m)만큼의 Result Set을 처리하는 과정에서 기존에 존재하던 컬렉션 내의 값들을 매번 비교해야 하므로 시간 복잡도는 2차 이상이 된다. 이는 컬렉션이 두 개일 때이며 컬렉션 수에 따라 지수 항 또한 증가한다.
hibernate는 대규모 데이터로 인한 메모리 문제를 우려한다기보다, 여러 List 초기화에 시간 복잡도가 엄청나 막는다고 보는 게 맞겠다.
Set은 어떤 문제를 가지나?
데이터의 중복과 무관하게 일반적으로 List를 선택하는 이유는 무엇일까? Set은 값을 추가하는 경우 등에서 지연 로딩의 이점을 살리지 못하기 때문이다.
기존에 존재하던 부모를 조회하고, 자식을 하나 더 추가해 보자.
TransactionStatus tx2 = platformTransactionManager.getTransaction(
TransactionDefinition.withDefaults());
try {
// 부모를 조회하고,
Parent findParent = entityManager.find(Parent.class, 1L);
Child1 child1_2 = new Child1();
child1_2.setName("child1_2");
// 자식을 추가한다. (cascade를 추가하지 않아 직접 영속화한다)
findParent.addChild1(child1_2);
entityManager.persist(child1_2);
entityManager.flush();
entityManager.clear();
...List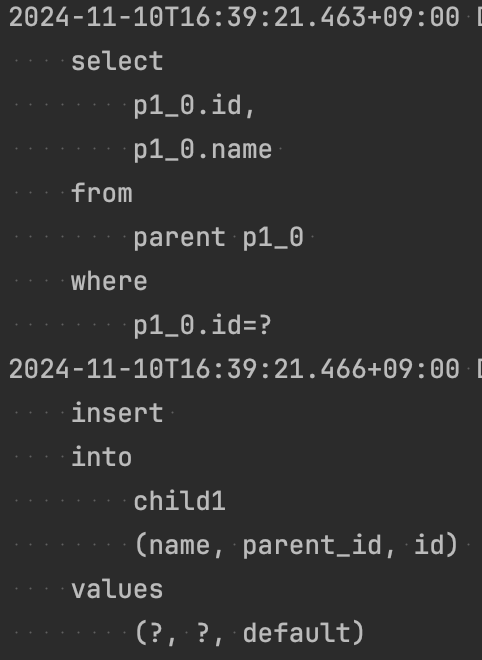 |
Set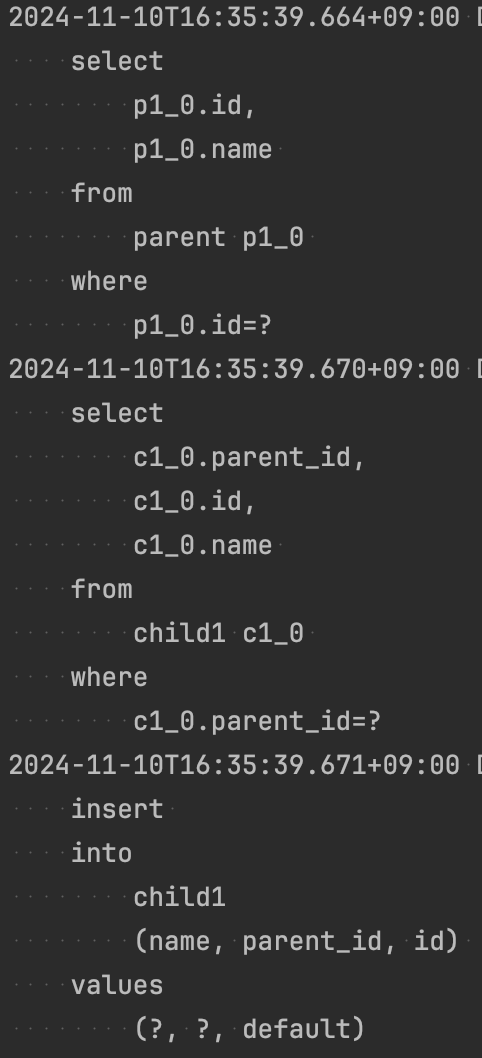 |
자식을 추가하는 과정에서 List의 경우 중복을 고려할 필요가 없으므로 바로 데이터를 삽입하는 반면,
Set의 경우 자료 구조의 특성상 삽입 시점에 해싱을 통한 데이터 중복을 검사해야 한다.
List와 달리 지연 로딩으로 값이 비어있던 Set(PersistentSet)을 초기화하기 위해 모든 자식을 가져오는 조회 쿼리가 추가로 발생한다.
즉, Set은 데이터 삽입 시 지연 로딩의 이점을 살리지 못한다.
즉시 로딩으로 여러 컬렉션을 가진 부모를 조회하면 어떨까?
비즈니스 특성 상 부모 - 자식이 언제나 함께 조회되어야 하는 상황이라면 즉시 로딩을 고려해 볼 수 있다.
위에서 hibernate는 여러 List를 하나의 조회 쿼리로의 초기화를 방지하는 것을 확인했다.
지연 로딩이었던 설정을 즉시 로딩으로 바꾸고 부모를 가져오면 어떤 쿼리가 발생할까?
@Entity
public class Parent {
...
@OneToMany(mappedBy = "parent", fetch = FetchType.EAGER)
private List<Child1> child1s = new ArrayList<>();
@OneToMany(mappedBy = "parent", fetch = FetchType.EAGER)
private List<Child2> child2s = new ArrayList<>();
...
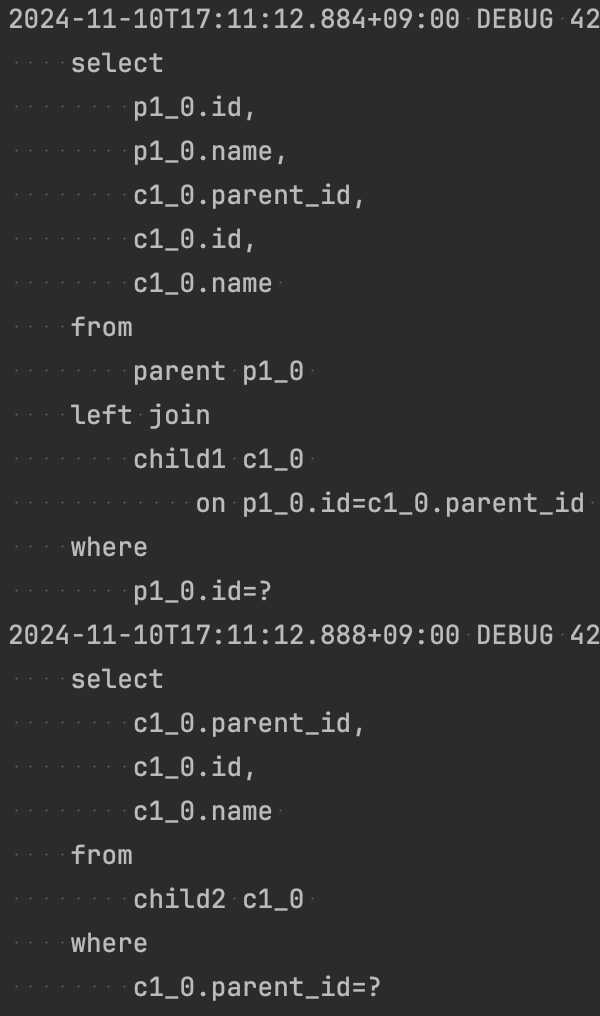
위에서 말했듯 여러 List에 대한 동시 조회는 비용이 너무 비싸므로, 알아서 하나의 List(PersistentBag)에 대해서만 초기화를 하도록 child1을 join 하여 가져오고, 별개의 쿼리로 child2를 가져온다.
추가로,
- 하나는 List, 나머지는 Set인 경우에도 컬렉션 별로 다른 쿼리를 통해 초기화한다
- 두 계층(Parent - Child1)이 아닌 더 많은 계층 (Parent - Child1 - ChildX..)의 경우에도 알아서 첫 Child1까지만 join으로 가져오고, 나머지 계층은 개별적인 쿼리로 가져온다.
이를 통해 hibernate가 List 초기화 과정을 최대한 간소화하는 방향을 선택함을 알 수 있다.
또한 즉시 로딩은 구현체(hibernate)의 판단에 따라 하나의 쿼리로 묶이지 않는 경우도 있음을 알았다.
'JPA' 카테고리의 다른 글
| [JPA] EntityManager의 merge() 동작 방식 유의점 (0) | 2023.09.26 |
|---|
- Total
- Today
- Yesterday
- GitHub Discussion
- 가변 인수
- Spring 테스트
- Spring Boot Monitoring
- comparing
- Jenkins 예약 배포
- 함수형 인터페이스
- MySQL 이벤트 스케줄
- 스프링
- logback-spring.xml
- GitHub Discussion Template
- MySQL
- Fromtail
- springboottest
- GitHub Discussion 템플릿
- multiplebagsfetchexception
- thenComparing
- JPA JSON
- invokedynamic
- java switch case
- 람다식
- Spring
- stubbing
- 자바
- Payload 암호화
- 의존성 주입
- RandomPort
- JPA
- 생성자 주입
- Java
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |