
티스토리 뷰
최근의 프로젝트에서 Spring Data JPA를 통해 상속관계를 사용했으나 적절하지 않음을 깨닫고 언제 슈퍼/서브타입을 사용해야 할지 정리하는 글입니다.
확장(Enhanced, Extended) ER과 슈퍼/서브타입
RDB의 엔티티 릴레이션(ER), 테이블은 정보를 저장하는 기본 단위이다.
전통적인 릴레이션 모델링만으로는 현실의 다양한 데이터들을 효율적으로 나타내기 어려워 이를 조금 더 추상화한 확장 ER의 개념이 나오게 되었고 데이터의 상속 관계를 나타내기 위한 슈퍼/서브타입에 대한 개념이 여기에 포함된다.
(명칭은 Super class & Subclass라 부르기도 하나 여기서는 슈퍼/서브타입 관계라 칭한다)
전통적인 모델링에서는 어떤 테이블의 하나의 열에 저장된 외래 키를 통해 다른 하나의 테이블만 탐색할 수 있다.
하지만 슈퍼/서브타입을 사용하면 객체지향의 상속의 개념과 같이 부모에서 다양한 자식 테이블로의 탐색이 가능하다.
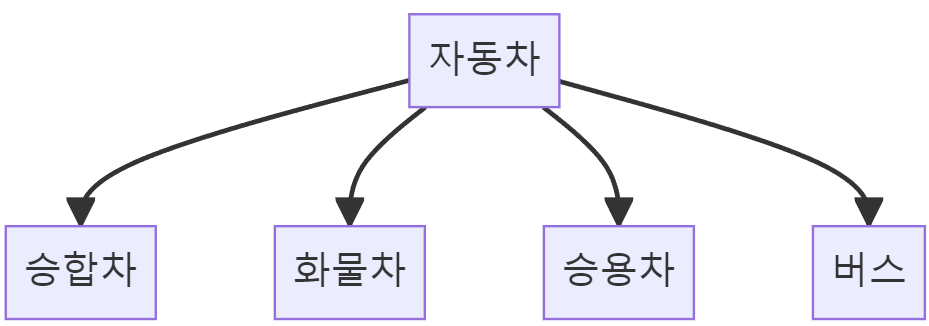
위와 같은 개념의 모델링이 가능해지는데, 다음의 예시는 슈퍼타입 테이블과 각각의 서브타입 테이블을 분리하고 서브타입 id와 종류를 통해 탐색하도록 하는 조인 전략에 대한 설명이다.
슈퍼타입인 '자동차'에는 서브타입들의 공통적인 속성들에 추가로 1. 서브타입의 키와 2. 여러 서브타입 중 어떤 서브타입인지에 대한 정보를 가진다. 각각의 서브타입 테이블들에는 추상화되기 어려운 정보를 별도로 가진다.
슈퍼타입인 '자동차' 테이블이 아래와 같이 구성된다면 '자동차' 테이블에서 공통적인 정보를 관리하고,
서브타입의 종류와 관련한 열을 통해 서브타입 테이블을 선택, 서브타입 id를 통해 서브타입의 행을 특정할 수 있다.
`자동차` 테이블의 예
| id | 이름 | 가격 | 서브타입의 id | 서브타입의 종류 |
| 1 | 스타리아 | 9999 | 1 | 승합차 |
| 2 | 포터 | 7777 | 1 | 화물차 |
부족한 근거를 바탕으로 슈퍼/서브타입의 도입
스터디 진행을 돕는 툴을 만드는 프로젝트를 진행하며 초기 버전에는 여럿이서 수준에 관계 없이 각자의 공부를 진행 가능한 뽀모도로 기법의 스터디 템플릿을 제공하기로 했다.
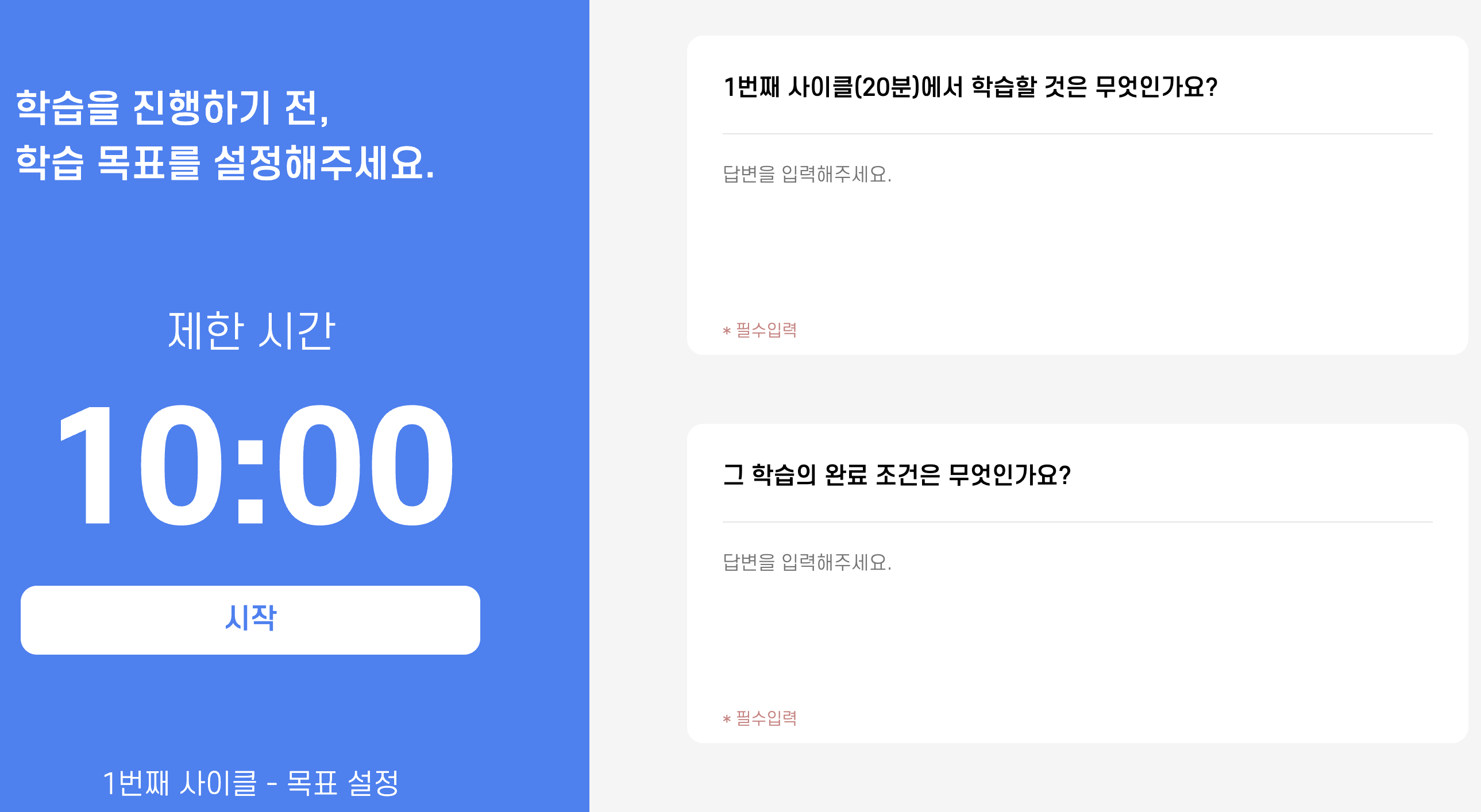
아래와 같은 모습으로 짧은 시간 내에 목표를 작성하고, 스터디를 진행하고, 활동에 대한 회고를 기록하는 사이클을 반복하는 방식이며
스터디를 개설하고 여럿이서 함께 진행 가능하여 타인이 작성한 목표와 회고를 볼 수도 있다.
 |
 |
이를 위해 DB에는 1. 개설된 스터디 방에 대한 정보(room), 2. 각 사용자의 스터디 진행 상황에 대한 정보, 3. 각 사용자가 기록한 계획 및 회고에 대한 정보를 저장할 필요가 있었다.
추후 다른 방식의 스터디를 위한 템플릿 추가가 매우 높은 확률로 예상되는 상황에서 위의 정보를 조인 전략을 활용한 슈퍼타입/서브타입 관계를 사용해 추상화(상속관계 매핑)하기로 결정했다. 템플릿이 다양화될 예정이라면 추상화하는 편이 이들을 웹서버 내에서 활용하거나 정보를 DB에서 관리하기에 용이할 것이란 섣부른 판단이었다.
Spring Data JPA를 사용하였으며 엔티티의 예시와 이로 인해 만들어지는 ERD는 아래와 같다.
설명에 필요하지 않은 정보는 최대한 생략하였다.
부모 클래스이자 슈퍼타입에 해당하는 Room 클래스, 뽀모도로 템플릿 관련 정보를 담는 PomodoroRoom 클래스
 |
 |

다양한 불편함
DB에는 슈퍼타입/서브타입 관계로의 뽀모도로 템플릿 관련 데이터를 모델링, Spring Data JPA를 사용해 상속을 통한 부모/자식 관계를 표현하는 과정에서 경험이 부족해 다양한 부분에서의 추가적인 고민을 하게 되었다.
Repository를 슈퍼와 서브타입 중 어떤 것에 대해 만들어야 하는가?
스터디 템플릿을 다양하게 제공할 예정이라면 서브타입인 대한 `Repository`를 별개로 만들어야 할까? 아니면 슈퍼타입에 대한 `Repository`를 만들어 공통적으로 사용해야 할까?

하나의 템플릿만 존재하고 서비스 로직이 간단한 초기 단계에서는 위와 같이 제네릭을 활용한 `Repository`를 만들어서 썼다.
하지만 조금 더 생각해보니 자식 객체, 서브타입에만 존재하는 정보를 포함한 DB 로직이 필요할 때는 대응이 어렵다.
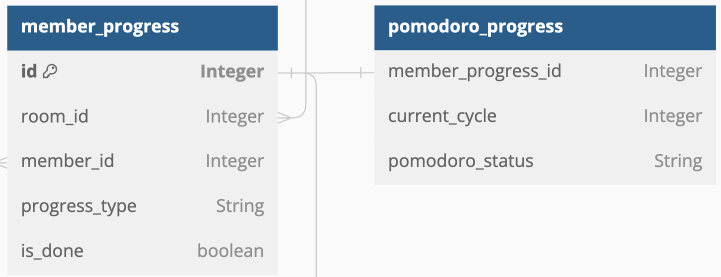
예를 들어 서브타입인 `pomodoro_progress`테이블의 `current_cycle` 혹은 `pomodoro_status`와 같은 정보를 통한 검색이 서비스에서 필요했다면 결국엔 추상화된 `MemberProgressRepository`만으로는 해결하지 못하고 `PomodoroProgressRepository`를 별도로 만들어야 했을 것이다.
결국 로직이 복잡해지고 서브타입이 많아지면 웹서버에서도 상속의 이점을 살리기 어려워 각각의 자식 클래스에 맞는 `Repository`를 만들어야 한다.
부모 - 자식 클래스의 `Repository`를 둘 다 만들어놓으면 개발 과정에서 슈퍼타입에 있는 정보는 부모 클래스에 대한 `Repository`를, 서브타입에 있는 정보는 자식 클래스에 대한 `Repository`를 번갈아 사용해야 하며 이는 어떤 정보가 슈퍼/서브타입에 있는지 매번 확인해야 하는 불편함, 그리고 실수로 이어지게 된다.
반대로 부모 클래스의 `Repository`는 만들지 않고 자식 클래스의 `Repository`들만 만드는 것도 방법인데, 이러한 경우는 위와 같은 혼란은 없으나 같은 부모를 둔 다양한 자식들의 `Repository`에 중복 로직이 들어가게 된다.
피할 수 없는 캐스팅
슈퍼/서브타입 관계가 많지 않다면 괜찮으나 위처럼 3개의 주요 테이블이 모두 슈퍼/서브타입으로 구성되며 이들을 함께 사용할 때 제네릭을 도입해도 캐스팅을 피하지 못하는 경우가 많았다.
다음의 ERD에서 JPA를 통해 '완료율이 높은 뽀모도로 스터디는 사이클 당 시간을 얼마로 지정하는지' 통계를 내고 싶다 가정하자.
한 스터디에 참여한 스터디원이 몇 명인지는 차치하고,
우선 `is_done`이 참인 `pomodoro_progress`를 가져오고 연관관계 매핑으로 `pomodoro_room`의 `time_per_cycle`을 모아 와야 한다.

제네릭을 활용하거나 자식 클래스의 `Repository`를 만들면 아래와 같이 자식 클래스를 완성하여 가져올 수 있다.
// repository
public interface MemberProgressRepository<T extends MemberProgress> extends JpaRepository<T, Long> {
List<MemberProgress> findByIsDoneTrue();
}
// service logic
MemberProgressRepository<PomodoroProgress> memberProgressRepository = new MemberProgressRepository<>();
List<MemberProgress> progresses = memberProgressRepository.findByIsDoneTrue();
`progresses`을 시작으로 `pomodoro_room`테이블에 저장된 사이클 당 스터디 시간 데이터인 `time_per_cycle`를 모아보는 로직을 구현해본다면 아래와 같다.
// Java 17을 사용해 toList()를 바로 쓸 수 있다. 데이터가 작아 stream을 위한 힙메모리가 충분하다 가정
progresses.stream()
.map(p -> ((PomodoroRoom)p.getRoom()).getTimePerCycle())
.toList();
`pomodoroProgress`에 연관된 `room`을 참조하면 이는 자식 클래스인 `PomodoroRoom`이 아닌 부모 클래스이므로 명시적으로 캐스팅을 한 뒤 `timePerCycle`을 다시 참조해야 한다.
상속관계로 매핑된 객체들끼리 협력하는 과정에서 자식 클래스의 정보가 필요하다면 캐스팅을 해야 한다는 점은 개발 과정에서 꽤나 불편하게 다가왔다.
재논의, 그리고 슈퍼/서브타입이 필요하지 않다 결정
위에서 설명한 두 예시 모두 컴파일 에러만을 내뱉으므로 크게 문제 될 상황이 만들어지진 않으나 개발 과정에서 매번 슈퍼타입과 서브타입에 저장된 정보가 무엇인지 구분해서 기억해 내야 했으므로 생산성이 높지 않았다.
초기에 템플릿이 하나밖에 없는 상황에서 미래에나 쓰일 확장성보다 당장의 떨어지는 생산성이 크게 다가와 팀원들과 정말 우리의 도메인에 상속관계 매핑이 필요한지 다시 고민해보게 되었다.
언제 상속관계 매핑이 빛을 발하는가?
슈퍼/서브타입으로의 상속관계 매핑이 유의미하게 활용되려면 부모 자식 엔티티 각각에서 처리해야 하는 유의미한 로직들이 있어야 한다.
그렇다면 현재의 비즈니스 로직에서 공통된 정보를 부모 클래스로 뽑아내고 이 공통된 정보에 대한 로직을 수행해야 하는 경우가 있어 추상화가 유의미한가?
고민해보니 위의 세 슈퍼/서브타입 관계 모두 그렇지 않았다.
1. `room`-`pomodoro_room`관계에서 `room` 테이블에서 관리하는 유의미한 정보는 `name`뿐이다.
2. `member_progress`-`pomodoro_progress` 관계에선 슈퍼타입인 `member_progress`의 유의미한 정보는 스터디가 끝났는지 여부인 `is_done` 뿐이다.
3. `member_content`와 `pomodoro_content`관계에서 슈퍼타입에는 심지어는 어떠한 유의미한 정보도 가지고 있지 않다.
이러한 상황에서 슈퍼타입만의 정보를 활용하는 경우는 통계를 위한 `count`연산을 슈퍼타입 테이블에서 하는 정도밖에 예상되지 않는다. 이것은 각각의 테이블에 나눠서도 충분히 할 수 있는 쉬운 로직이다.
또한 스터디 템플릿이 추가되는 상황을 가정해도 다양한 템플릿을 통한 방 정보, 진행 정보, 기록 정보에 대한 더 많은 추상화가 될 것 같지는 않다. 스터디 템플릿이라는 도메인 자체가 다양성이 워낙 커 공통된 내용을 뽑아내기 어렵기 때문이다.
결과적으로 스터디 템플릿이라는 것이 너무 다양해 이것을 추상화할 공통적 요소가 많지 않았으며,
억지로 추상화하였을 때 추상화된 슈퍼타입만을 활용할 일이 없었다. 이에 반해 개발 생산성은 여러모로 떨어진다.
따라서 템플릿에 대한 추상화를 하루라도 빨리 걷어내기로 결정하였고 아래와 같은 형태의 ERD가 완성되었다.

언제 상속관계 매핑을 사용해야 하는지 더 잘 알게 된 시간이었다.
'하루스터디' 카테고리의 다른 글
| 정적 파일, 웹 서버, DB 스키마까지 무중단 배포 시도하기(1) - 무중단 배포 과정 계획하기 (1) | 2023.10.15 |
|---|---|
| 우리 서버는 어느 정도의 부하를 견딜 수 있을까 - 부하 테스트 계획 & 실행 (1) | 2023.10.10 |
| 밤에 DB와 서버를 안전하게 예약 중단 배포하기 (0) | 2023.09.04 |
| SpringBoot Application과 Grafana 기반의 Metric & Log 모니터링 (4) | 2023.08.13 |
| RDB에 JPA로 변경 가능성이 높은 데이터를 JSON으로 저장하기 (0) | 2023.07.16 |
- Total
- Today
- Yesterday
- GitHub Discussion
- 우테코 5기
- springboottest
- Fromtail
- RandomPort
- 함수형 인터페이스
- JPA
- java switch case
- stubbing
- 우테코
- 스프링
- Spring Boot Monitoring
- invokedynamic
- 람다식
- multiplebagsfetchexception
- 자바
- Java
- 의존성 주입
- 우테코 프리코스
- Spring 테스트
- Payload 암호화
- 생성자 주입
- GitHub Discussion Template
- JPA JSON
- MySQL
- Spring
- MySQL 이벤트 스케줄
- Jenkins 예약 배포
- logback-spring.xml
- GitHub Discussion 템플릿
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |