
티스토리 뷰
간단한 SpringBoot Rest Api 서버를 배포한 뒤 해당 서버가 설치된 AWS EC2에 대한 모니터링이 필요해졌다.
본 글은 설치 및 운영에 대한 가이드보다 어떠한 배경을 고려하여 도입하게 되었는지를 위주로 작성했다.
고려 사항과 목표
모니터링 시스템 구축 시 고려한 제약 사항은 아래와 같다.
- 배포한 Api 서버가 초기 단계여서 아직 부하가 거의 없는 상황
- EC2에 대한 ssh 접속이 사내 네트워크에서만 접속이 가능하여 외부에서 대시보드로 상황을 확인할 수 있어야 함
- 보안을 위해 모든 IP에서 접속 가능한 EC2의 인바운드 규칙은 443, 3000, 8080 포트로 제한이 되어있으며 EC2 한 대는 443과 8080은 이미 HTTPS 접속과 Api 서버에 사용 중이어서 사실상 3000번만 사용이 가능. 아웃바운드는 자유롭다.
- 가용 자원은 이미 다른 작은 프로세스가 실행 중인 EC2(t4g.small) 2대뿐
외부 네트워크에서도 배포 및 운영 과정에서 서버의 상태를 꾸준히 모니터링해야 했으며,
동시에 한정된 자원에서 서비스의 응답 속도가 크게 영향받지 않는 수준으로 완전히 새로운 모니터링 시스템이 구축되어야 했다.
간단하게 다양한 모니터링 방법들에 대해 알아보고 적합한 방법을 시험해 보았다.
목표한 사항은 아래와 같다.
- SpringBoot App이 실행 중인 인스턴스에 대한 전반적인 메트릭 모니터링
- SpringBoot App이 남기는 로그들을 인스턴스 외부에서 확인
- 각 서비스의 세부적인 튜닝보다는 메트릭과 모니터링 시스템을 빠르게 구축하는 것을 목표로 한다.
고려한 상용 서비스
1. CloudWatch

AWS의 각종 리소스 및 해당 리소스 내에서 실행되는 애플리케이션에 대한 실시간 모니터링이 가능하다.
AWS EC2와 연계하기 쉽고 대시보드, 알림, 통합 로그 등 다양한 기능을 지원한다.
간편하고 강력하나 기존의 EC2에 Cpu 및 Ram에 여유가 있어 간단한 모니터링 구축을 하기에 아직은 충분하다 판단,
추가적인 비용이 청구되므로 고려 대상에서는 제외했다.
2. ELK 스택(Elasticsearch, Logstash, Kibana)
로그 모니터링에 특화된 Elasticsearch, Logstash, Kibana 세 개를 함께 사용하는 ELK 스택.
Elasticsearch로 인해 유연한 로그 분석이 가능하다. 검색 및 필터링 기능이 강력.
메트릭 데이터보다는 로그 처리에 특화되어 있다.
3. Grafana와 연계한 모니터링 시스템


Grafana - Prometheus는 서버 메트릭 수집 및 시각화를 위해 함께 쓰인다.
Prometheus는 서버 메트릭을 처리하며 Grafana를 함께 사용하면 이 메트릭 데이터를 더 효과적으로 시각화할 수 있다.

추가적으로 Promtail - Loki를 각각 Application Server, Monitoring Server에 설치하면 SpringBoot App에서 발생시킨 로그 데이터를 Monitoring Server에서 Grafana가 처리 가능한 형태로 가공하고 저장한다. (Loki Stack)
Promtail, Loki, Prometheus 그리고 Grafana를 선택
추가 비용이 소요되는 CloudWatch를 제외한 나머지 선택지 중
- 로그와 서버 메트릭 모두를 모니터링해야 한다는 점
- ELK보다 학습 소요 시간이 적다고 알려져 있으며 Prometheus와 Loki의 설정을 위한 YAML의 형식이 유사해 설정이 어렵지 않다는 점
- 이미 앱에서 LogBack으로 구분된 로그(모든 로그, WARN과 ERROR에 대한 로그, Http 요청/응답)를 남긴다는 점
세 가지로 인해 Promtail, Loki 그리고 Prometheus, Grafana 쪽으로 마음이 기울었다.
사용할 두 EC2(t4g.small) 모두 CPU 상태는 매우 양호했으나 모니터링 관련 프로세스들을 추가적으로 실행시키면 기본 RAM 2g로는 버티지 못할 것이 분명하고 이에 반해 스토리지는 여유로워 추가적으로 스왑 메모리를 2g, 4g 각각 설정한 뒤 진행했다.
SpringBoot Actuator와 Prometheus의 연계
Web Server Side
SpringBoot를 사용하므로 서버 메트릭 수집은 Prometheus를 통해 매우 쉽게 할 수 있었다.
Build.gradle에 애플리케이션 모니터링을 위해 actuator를 추가하고 prometheus를 위한 micrometer를 추가하면 별도의 세부 설정 없이도 관심을 가질 만한 대부분의 서버 메트릭을 수집해 준다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus'
}
application.yml에 외부 접속을 위한 endpoint를 열어준다.
management:
endpoints:
web:
exposure:
include: prometheus
endpoint:
prometheus:
enabled: true
/actuator/prometheus 에 접속하면 상상할 수 있는 대부분의 서버 메트릭을 이미 수집하는 것을 볼 수 있다.
다음의 메트릭들을 모두 포함한다.
- CPU 사용량
- GC
- HTTP 요청, 응답 시간
- DataSource
- 가동 시간
- Logback 관련
아쉽게도 Logback으로 남긴 로그 자체를 볼 수는 없다.
설정한 endpoint에 들어가면 아래와 같이 지속적으로 갱신되는 메트릭을 볼 수 있다.

actuator를 사용하는 방식을 선택한다면 외부인이 접속 가능한 endpoint를 하나 여는 것과 같으므로 보안에도 신경을 써야 한다.
NginX와 같은 Reverse Proxy로 접근을 제한하거나 Spring Security, 혹은 IP Whitelisting과 같은 절차를 추가해 주는 것이 좋다.
Monitoring Server Side
WAS에서 열어둔 EndPoint를 통해 서버 메트릭 수집이 가능해졌으므로 이제 다른 서버에서 이 메트릭을 가져와 가공해야 한다.
Prometheus
WAS가 만든 데이터를 Monitoring Server의 Prometheus에서 수집해 Grafana가 시각화할 수 있는 형태로 가공하도록 한다.
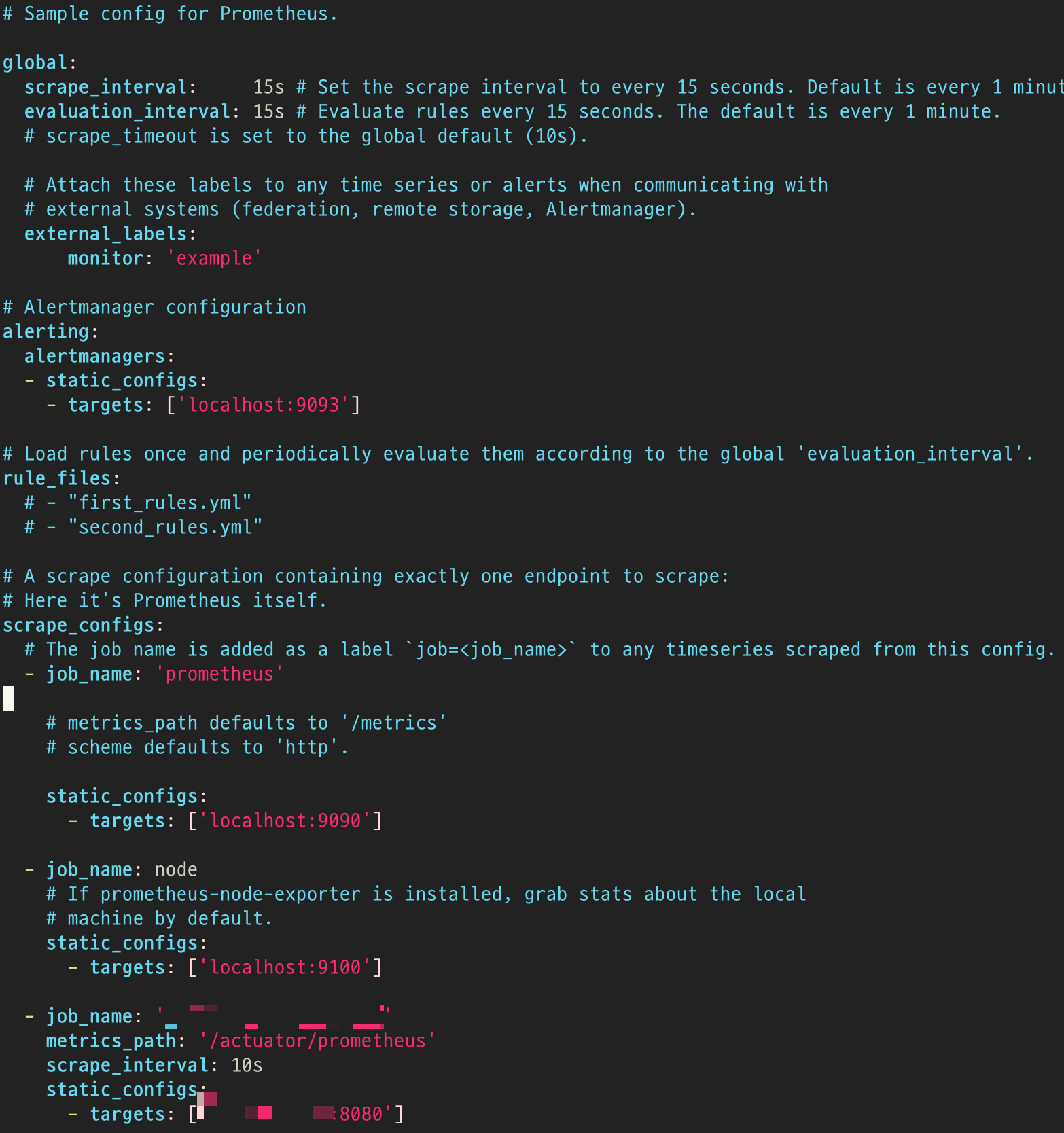
기본 제공되는 yml에도 친절하게 주석이 많다.
기본 설정에서는 15초마다 설정된 job들에 대한 데이터를 수집한다.
여기서는 세 개의 job을 설정했는데 수집하는 데이터는 아래와 같다.
- Monitoring Server의 Prometheus 프로세스에 대한 Metric. 메모리 사용, 처리량, 쿼리 성능 등을 포함.
- 추가적으로 설치한 Node Exporter가 수집하는 Monitoring Server의 CPU, RAM, Disk 등의 리소스
- 목표한 Spring Boot App의 actuator로 열어둔 endpoint를 통한 데이터
각 job에 대한 scrape 주기 등을 더 세밀하게 조정할 수 있다.
Grafana
Prometheus 자체적으로도 기본적인 시각화가 가능하나 보다 강력한 형태는 Grafana에서 제공한다.
Grafana를 선택한 큰 이유 중 하나로, 다양한 대시보드 템플릿을 손쉽게 선택해서 사용할 수 있다.
이미 Spring Boot의 Prometheus DataSource를 잘 시각화하는 대시보드가 존재하며 나의 경우 프로젝트가 Spring Boot 3 이상을 사용하여 그에 맞는 대시보드를 선택했다.
https://grafana.com/grafana/dashboards/19004-spring-boot-statistics/
Spring Boot 3.x Statistics | Grafana Labs
Thank you! Your message has been received!
grafana.com
대시보드의 적용은 매우 간편하다.
Dashboards > New > Import에서 사용할 대시보드의 ID를 적고 Load 하기만 하면 된다.


이것으로 손쉽게 SpringBoot 서버에 대한 메트릭을 대시보드로 확인할 수 있게 되었다.
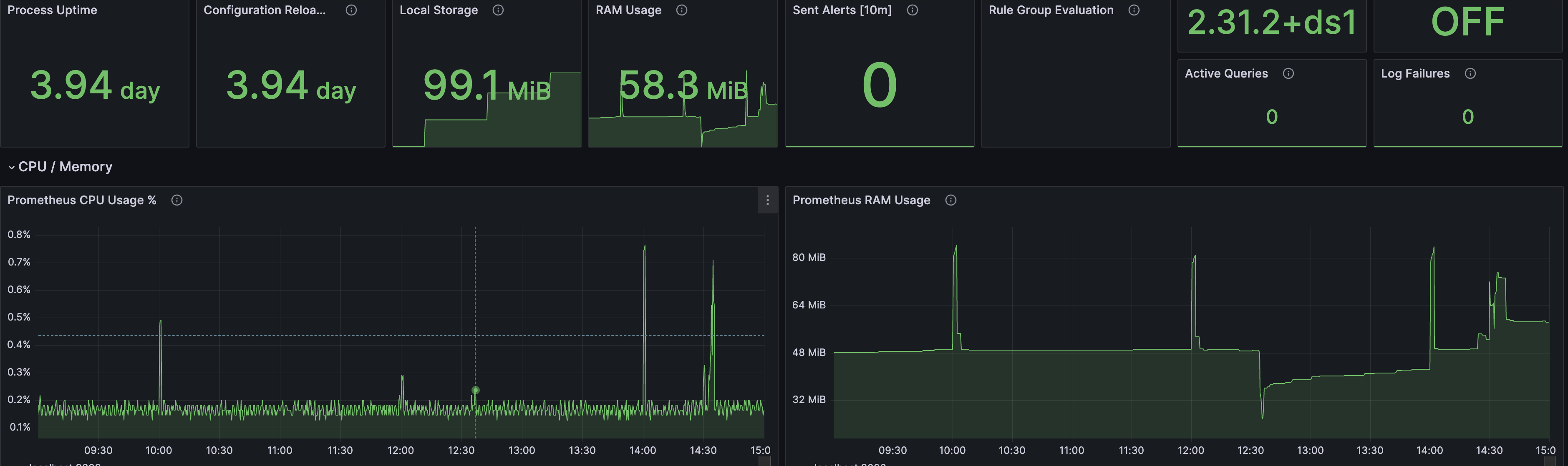
또한 비슷한 방법으로 Prometheus 자체에 대한 데이터도 별도의 대시보드로 시각화할 수 있었다.
프로세스가 100MB 이하의 램을 점유하고 있는 것을 확인할 수 있다.
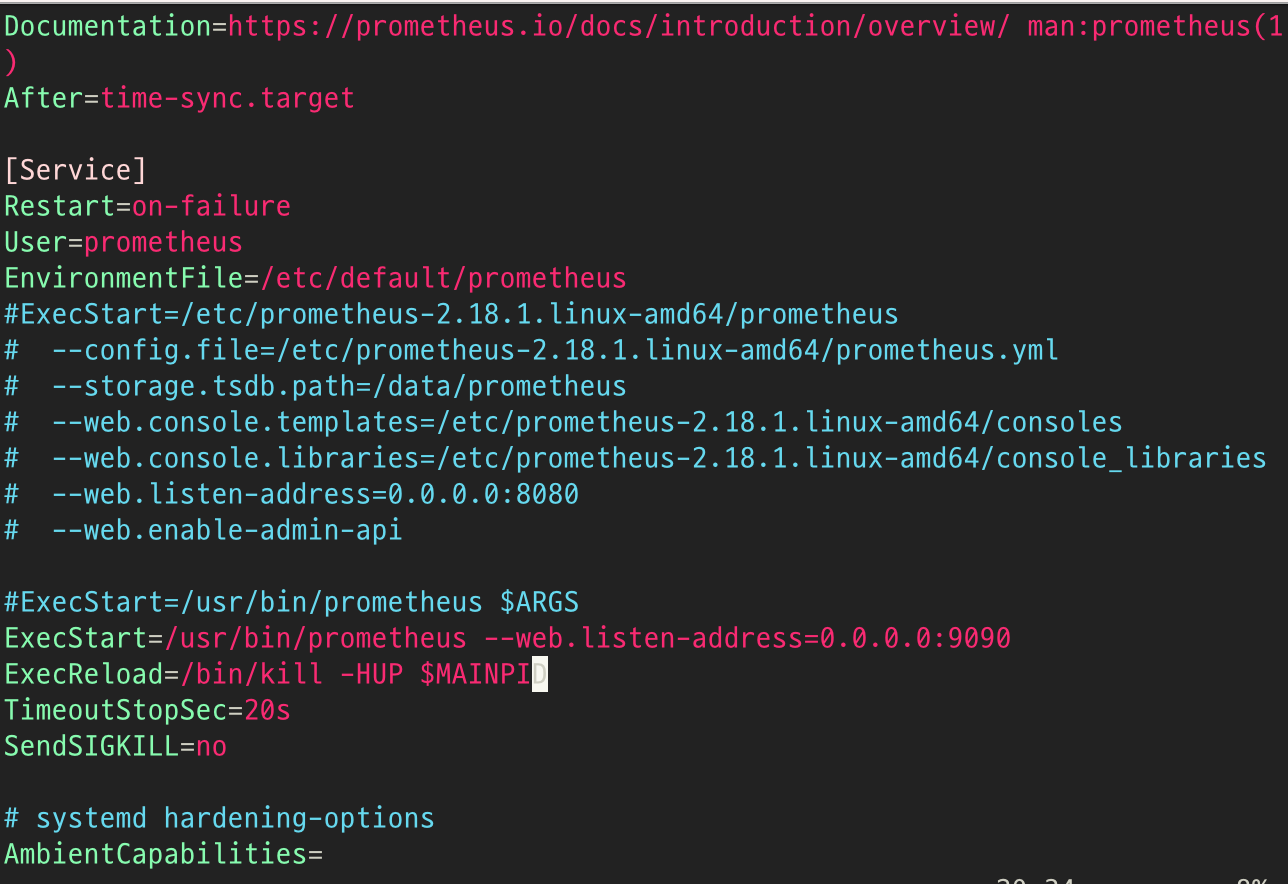
prometheus에 대한 추가적인 설정은 프로세스를 실행시킬 때 옵션을 주거나
위와 같이 systemd를 사용하면 prometheus.service 파일을 통해 옵션을 미리 지정할 수 있다.
스토리지 관련 옵션에 대해서는 우려가 되어 찾아보았는데 기본 설정에서는 데이터를 15일간 유지한다.
아래와 저장 날짜를 같이 지정하거나 .service 파일에 명시하면 된다.
prometheus --config.file=prometheus.yml --storage.tsdb.retention.time=30d
https://prometheus.io/docs/prometheus/latest/storage/#operational-aspects
Storage | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
당장은 이 이상으로 Prometheus metric을 볼 일은 없을 것이라 예상되어 기본적인 설정만으로 system metric monitoring 설정은 마쳤다.
Promtail과 Loki
목표했던 Logback으로 남긴 로그를 같은 대시보드에 띄울 차례다.
이미 Logback으로 로컬에 1. 전체적인 로그, 2. WARN 및 ERROR 수준의 로그, 3. HTTP 요청, 응답에 대한 주요 정보 로그 세 가지를 별도의 파일에 남기고 있다.
Logback 설정을 통한 로그 파일 분리 방법이 궁금하다면 기존 글을 참고하길 바란다.
2023.05.26 - [Web/Spring] - logback-spring.xml을 사용해 로그 커스터마이즈하기
WAS 이외의 지점에서 발생하는 로그나 로그에 대한 아카이빙 등은 차치하고, 위의 세 로그 파일을 Promtail과 Loki를 통해 Grafana가 보여줄 수 있는 형태의 Datasource로 가공하고 하나의 대시보드에 로그들을 띄운다.
Web Server Side
Promtail
서버 메트릭의 경우 SpringBoot에 추가한 micrometer를 통해 손쉽게 수집하고 actuator를 통한 endpoint로 외부에서 데이터를 가져가기가 쉬웠지만 Logback이 남긴 로그를 외부에서 가져가도록 하려면 별도의 설정이 필요하다.
이 작업을 Promtail을 통해 진행한다.
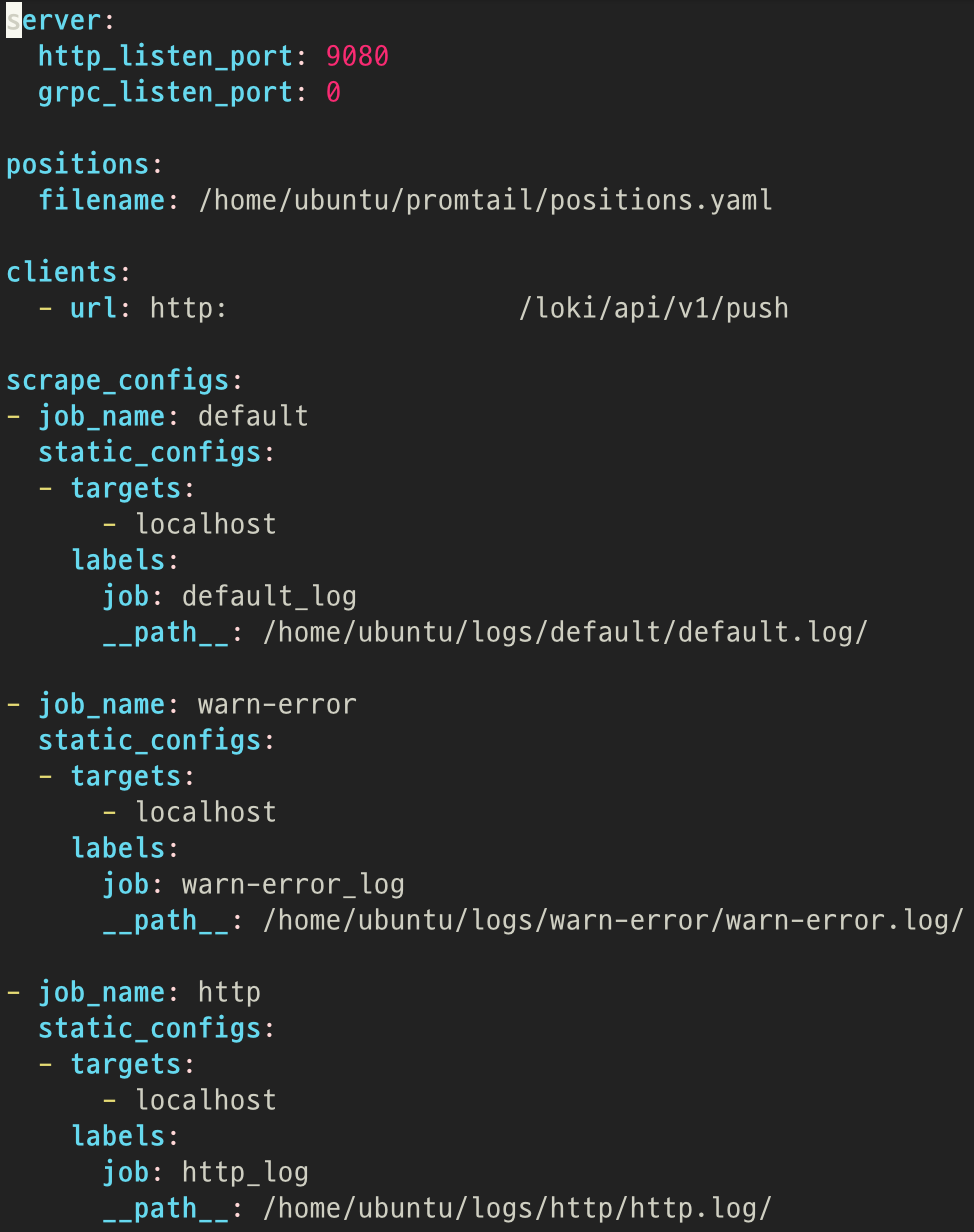
이미 보았던 prometheus 설정을 위한 YAML과 방식이 유사하다. Grafana Lab에서도 설정 방식이 크게 다르지 않다고 설명한다.
promtail 설정 파일을 위와 같이 구성한 뒤 프로세스를 실행시키면 clients에 명시된 Monitoring server로 각 job에 명시된 파일들을 전송한다. 세 종류의 로그를 각각의 job을 통해 처리하도록 하였다.
Monitoring Server Side
Loki
WAS와 함께 설치한 Promtail은 로그 데이터를 Loki로 전송한다.
Loki는 Log를 위한 DBMS라 볼 수 있다. (Distributor, Ingester 등 여러 컴포넌트의 집합체다)
간단히 알아보았을 때 전통적인 DBMS와는 아래의 특징적인 차이가 있다.
- 로그 특성에 맞게 시계열 데이터 저장에 특화되어 있다.
- 로그(chunk) 외에 별도의 Label, TimeStamp를 통한 인덱싱 데이터를 함께 저장한다
- 데이터는 별도의 DynamoDB 등을 사용할 수도 있으며 FileSystem을 사용해도 괜찮다.
- Prometheus처럼 SQL이 아닌 PromQL을 통해 데이터를 질의. Grafana에서도 PromQL을 통해 데이터를 커스텀 가능하다.
- 대량의 로그 처리를 위해 트랜잭션 및 일관성을 일부 포기하는 대신 성능을 취한다.
더 자세한 내용과 가이드는 Grafana Loki 페이지에서 많이 찾아볼 수 있다.
https://grafana.com/docs/loki/latest/storage/
Loki는 이 데이터를 Grafana에서 처리할 수 있는 형태의 DataSource로 만든다.
아래와 같이 기본 설정에 Retention 관련 정보만 수정하여 사용하였다.

간단히 살펴보았을 때 별도의 설정을 하지 않았으므로 데이터들을 filesystem으로 관리한다.
또한 별도의 설정이 없으면 chunk 및 index 데이터에 대한 저장은 무한히 이루어지므로
장기 저장소에서의 잔존 시간을 retention_period 옵션으로 7일로 제한하였다.
https://grafana.com/docs/loki/latest/operations/storage/retention/#configuring-the-retention-period

정상적으로 설정되었다면 Prometheus와 마찬가지로 Loki를 추가한 뒤, Build a dashboard를 통해 해당 데이터를 보여주는 대시보드를 구성할 수 있다.
Grafana 결과물
최종적으로 서버에 대한 메트릭 및 로그까지 함께 실시간으로 볼 수 있는 대시보드가 구성되었다.
당장은 Http 요청에 대한 응답 속도 그리고 로그를 통한 서버의 정상 작동 여부를 우선적으로 볼 듯하다.
또 로그에 대한 TimeZone이 다르게 표시되는데 Promtail인지 Loki 설정 문제인지 아직 찾아보지는 못했다.
추가로 Grafana를 사용하면 Loki를 통한 로그를 바탕으로 Slack 알람 등이 가능하다. 이것이 서버에 얼마나 부하를 주는지는 테스트해보지 못했다.
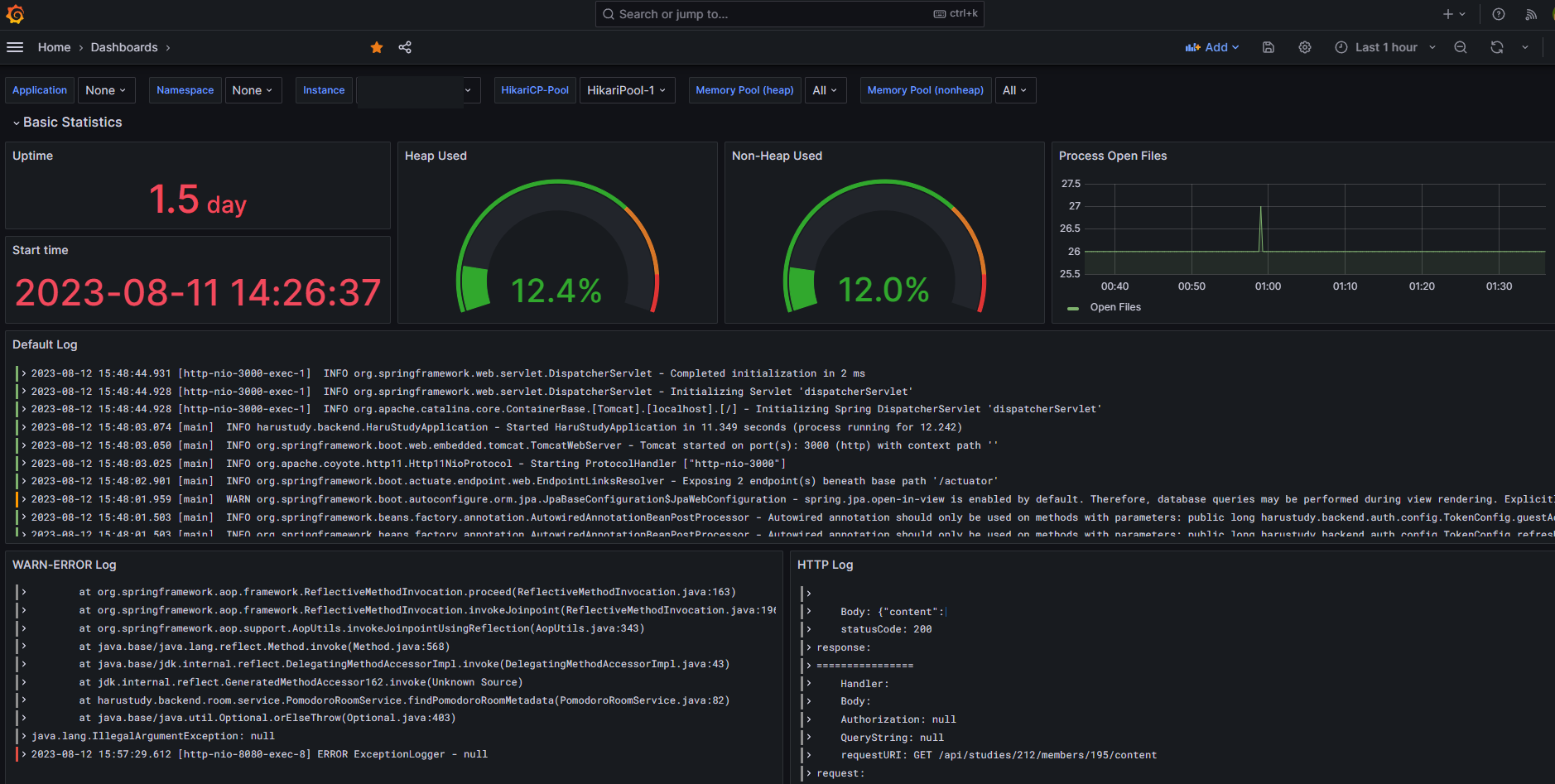
구축이 끝난 다음 날 재택으로 진행하며 Grafana를 통해 서버 접속 없이도 바로 트러블슈팅을 하는 팀원을 보니 뿌듯..
앞으로의 고려 사항
당장은 서비스 자체의 규모가 작고 로그에 대한 검색 등이 급하지 않아 대시보드에 띄우는 정도로만 구성하였다.
서버 메트릭과 서비스 로그도 구분되면 좋겠으나 당장의 자원에서는 그러기는 어려웠다.
로그에 대한 세부적인 저장 등은 필요성이 대두되면 다시 고민해 볼 예정이다.
성능 관련


트래픽이 거의 없는 상태이긴 해도 t4g.small에 하나를 초과하는 WAS와 모니터링 환경까지 붙였을 때 RAM이 버텨줄지가 가장 걱정이었는데 스왑메모리 덕에 문제가 발생하진 않았다. 기본 2기가 램은 두 서버 모두 사용 중이며 스왑도 일부 사용한다.
모니터링 서버에서는 기존 프로세스의 CPU-Intensive 한 작업이 있어 조금 걱정했는데 해당 작업 도중에도 모두 문제가 발생하지 않았다.
띄우는 것은 문제가 없었으니 다음으로 걱정한 부분은 처리 속도였다.
스왑메모리로 인해 일부 요청에 대한 처리 속도가 늦어질 것을 많이 걱정했는데,
하루 이상 지켜보았을 때 현재 로드에서는 모든 요청이 30ms내에 처리되는 것을 확인했다.
아직은 스왑 영역의 사용량이 미미해서 그런 것으로 예상된다.
추후 앱이 커져도 쓸만한 수준인지는 부하테스트를 통해 다시 확인할 예정이다.

다행히 자료가 많아 현재 필요한 모니터링에 대해서는 이틀이라는 비교적 짧은 시간 내에 구축이 가능했다.
각 기술들에 대해 지켜보면서 튜닝까지 하진 않았지만 당장의 사용 수준에선 충분한 듯하고,
이후 개발서버 도입 및 수평 확장 시에도 오케스트레이션이 충분히 가능한지는 파악해 본 뒤 가능하다면 도커 기반으로 옮겨야겠다.
너무 얕게 알고 넘어감이 아쉽기는 하나 시간이 한정적인 상황에서 세부적인 튜닝보다는 전체적인 시스템을 구축하는 것이 목표였으므로 이 정도로 만족하기로 했다. DevOps 쪽에서 이외에도 고려할 사항이 너무 많아 당장 발전시키기는 어려울 듯하다.
'하루스터디' 카테고리의 다른 글
| 정적 파일, 웹 서버, DB 스키마까지 무중단 배포 시도하기(1) - 무중단 배포 과정 계획하기 (1) | 2023.10.15 |
|---|---|
| 우리 서버는 어느 정도의 부하를 견딜 수 있을까 - 부하 테스트 계획 & 실행 (1) | 2023.10.10 |
| 밤에 DB와 서버를 안전하게 예약 중단 배포하기 (0) | 2023.09.04 |
| 언제 JPA를 통해 슈퍼/서브타입을 사용해야 할까? (0) | 2023.07.30 |
| RDB에 JPA로 변경 가능성이 높은 데이터를 JSON으로 저장하기 (0) | 2023.07.16 |
- Total
- Today
- Yesterday
- 생성자 주입
- GitHub Discussion Template
- RandomPort
- Spring 테스트
- 의존성 주입
- Java
- 자바
- 람다식
- logback-spring.xml
- Jenkins 예약 배포
- GitHub Discussion 템플릿
- JPA
- java switch case
- invokedynamic
- thenComparing
- GitHub Discussion
- Spring Boot Monitoring
- 스프링
- Spring
- Fromtail
- springboottest
- MySQL 이벤트 스케줄
- 가변 인수
- JPA JSON
- Payload 암호화
- multiplebagsfetchexception
- MySQL
- comparing
- stubbing
- 함수형 인터페이스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |