
티스토리 뷰
정적 파일, 웹 서버, DB 스키마까지 무중단 배포 시도하기(2) - Trigger로 무중단 DB 마이그레이션 진행하기
Jaehee Jeon 2023. 10. 29. 17:58
버전이 올라가며 이전, 이후 버전의 DB 스키마가 크게 바뀌었다.
주요 테이블의 네이밍이 수정되었고 서비스 로직이 변경되며 컬럼의 위치도 일부 수정되었다.
개인 별로 저장되던 스터디 참여자들의 진행 정보가 기획이 수정되며 함께 관리되도록 바뀌었다.
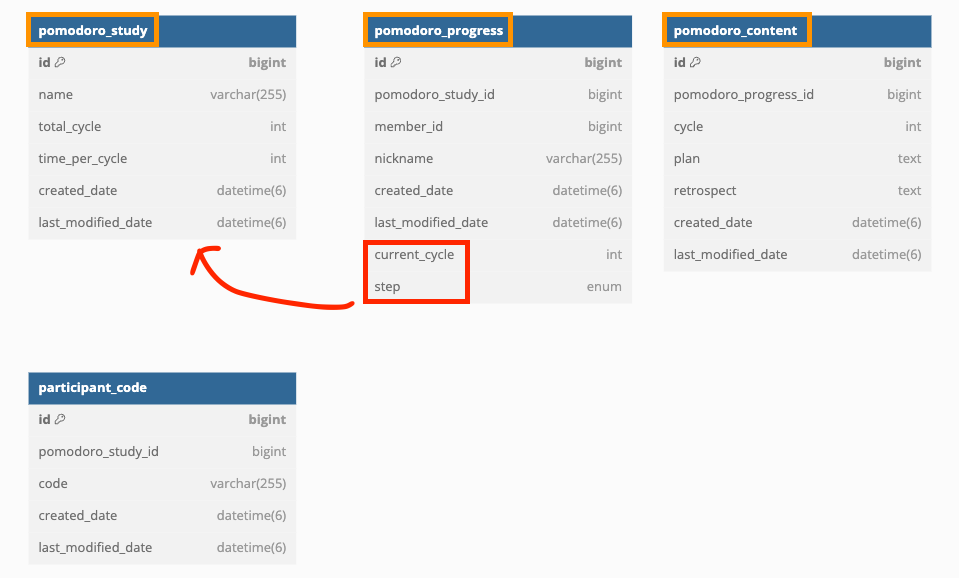

문제: 스키마는 바꼈지만 이전 버전의 데이터도 신버전에서 실시간으로 보고 싶다
스키마의 변경 자체는 크진 않지만 신규 배포를 무중단으로 진행해야 한다는 점이 가장 큰 문제였다.
서비스에는 다음의 세 주요 기능이 존재한다.
1. 스터디 함께 진행하기
2. 혼자 공부하기(다인 스터디를 혼자 진행하는 형태)
3. 자신의 스터디 기록 조회하기
이번 배포에서는 기능이 빈약한 '1. 스터디 함께 진행하기'에 실시간 동기화 기능을 추가하는 것이 가장 큰 변경이었고,
기능이 변경되면 이전 버전과 아예 호환이 되지 않기에 구버전에서 기능을 사용하지 못하도록 선제조치를 진행했다.
배포 과정에서도 '2. 혼자 공부하기'와 '3. 자신의 스터디 기록 조회하기'는 중단이 없어야 하므로 다음의 제약사항을 해결해야 했다.
1. 이전, 이후 버전이 다른 WAS로 요청을 보내지만 사용자가 생성하는 기록은 각자의 버전에 맞춰 DB에 생성되거나 변경되는 동시에,
2. 신규 버전에선 이전 버전까지의 기록을 통합하여 확인할 수 있어야 한다.

즉, 이전 버전에서 쓰인 데이터는 1. 이전 버전대로 저장도 되며 2. 실시간으로 신버전에 맞게도 저장되어야
배포 직후 신버전을 내려받아 사용하는 사람이 구버전에서 완료한 스터디 기록을 바로 조회할 수 있다.
실패한 시도: 짧은 간격의 Schedule을 돌려 새로 추가된 내용을 신규 테이블에 복제하자
DB를 구버전, 신버전으로 나누어 해결하는 방법도 있을지 모르겠으나 이는 시간이 부족한 상황에서 선택하기 어려운 방법이었다.
불행인지 다행인지 테이블의 이름이 바꼈으므로 신버전에서 쓸 새로운 테이블을 만들고 구버전 테이블에 새로 쓰이는 데이터를 추가로 복사해서 넘겨주는 방식을 고려했다.
옛 Schema에 맞춰 삽입된 데이터를 어떻게 새로운 table에도 저장할 수 있을까?
우선 익숙한 MySQL Schedule을 사용해 해결하는 방법을 구상했다.

'lastly_updated_pks'는 마지막으로 복제 작업을 완료한 컬럼의 PK를 기억하기 위함이다.
'mapping table'은 다른 테이블의 데이터 복제 시 FK를 참조해야 하는 경우가 있어 필요하다.
LAST_INSERT_ID() 함수를 통해 신규 테이블에 insert하며 생성된 auto_increment_id를 얻을 수 있다.
이를 바탕으로 fk가 필요한 다른 테이블에도 삽입 작업을 한다. (LAST_INSERT_ID()와 관련해선 유의해야 할 점들이 있다)
한 번의 스케줄 내에서는 아래의 동작들을 한다.
0. 짧은 간격의 스케줄이 돌기 전 구버전 사용자는 old_table에 기록을, 신규 사용자는 new_table에 기록을 남긴다.
1. 스케줄 시작 시 mapping table에서 마지막으로 복사 작업을 한 데이터의 pk를 가져온다. (old table id = 7)
2. 범위 검색을 통해 마지막 스케줄 이후 old_table에 새로 삽입된 row들을 가져온다(old table id = 8, 9)
3. new_table에 스키마에 맞게 insert문을 날린다. (new_table id = 12)
4. 기존 테이블 - 복제된 데이터의 pk 정보를 mapping table에 기록한다
5. 6. 추가적인 데이터에 대해서도 insert 및 mapping table의 기록을 진행한다
7. 복제를 완료한 old table의 id를 갱신한다(7 -> 9)
총 테이블이 네 개가 변경되므로 네 테이블 모두에 대한 schedule이 필요하고, 이때 신규 테이블에서 사용 중인 FK를 참조하기 위해 각 테이블의 mapping table을 별도로 관리한다. (실제로 FK를 사용하고 있진 않으나 연관성을 나타내기 적절해 표현상으로만 쓴다.)
방법이 조금 복잡하고 일시적으로 성능은 감수해야겠지만 특정 시점부터 구 테이블에 삽입된 데이터는 신규 테이블에도 맞게 삽입된다.
적절히 짧은 시간마다 schedule이 돌게 하면 추가된 사항만 점검하므로 사용자가 체감하지 못할 수준으로 복제된다.
열심히 스케줄을 다 작성해가는 도중...
팀원이 '이거 변경에 대해서는 어떻게 복제하지?'
아....
새로운 시도: Trigger를 사용하자
짧은 간격의 스케줄로 Table Full Scan을 하며 변경을 찾아내는 건 말이 안 된다.
잠시, 아니 좀 길게 낙담했다가...
문득 MySQL에서는 바이너리 로그로 Master-Slave 간 변경을 반영하는데 이처럼
사용자 수준에서 변경(INSERT, UPDATE, DELETE)에 대한 처리를 명시적으로 해 줄 방법은 없을까? 하는 생각이 났다.
조금 뒤져보니 너무 다행히도 MySQL에는 Trigger라는 기능이 있었다.
일종의 Stored Procedure이며 테이블 단위로 INSERT, UPDATE, DELETE에 대한 이벤트 발생 시 사용자가 지정한 행위를 하도록 만들 수 있다.
아래처럼 Trigger를 만들어주었다.
DELIMITER $$
CREATE TRIGGER pomodoro_study_insert_trigger
AFTER INSERT
ON pomodoro_study
FOR EACH ROW
BEGIN
INSERT INTO study(name, total_cycle, time_per_cycle, current_cycle, step, created_date, last_modified_date) VALUES (NEW.name, NEW.total_cycle, NEW.time_per_cycle, 1, 'PLANNING', NEW.created_date, NEW.last_modified_date);
INSERT INTO pomodoro_study_to_study(pomodoro_study_id, study_id) VALUES
(NEW.id, LAST_INSERT_ID());
END $$
DELIMITER ;
이렇게 적용하면 'pomodoro_study'라는 테이블에 INSERT가 발생했을 때 내가 지정한 작업,
'study'테이블에 INSERT를 수행하고, 위에서 언급한 mapping table에도 해당 정보를 기록한다.
(모든 테이블의 레코드 생성 시점이 같은 것이 아니어서 여전히 FK 참조를 위해 mapping table은 필요했다)
이와 같은 형태로 다른 테이블에도 필요한 내용의 INSERT, UPDATE Trigger를 모두 준비해 두었다.
이제 남은 고민은 예상처럼 Transaction 처리가 깔끔하게 되나? 였다.
WAS 사용 시점은 NGINX를 통해 제어가 가능하므로 '신규 테이블을 생성하는 DDL'은 먼저 입력해 두어도 문제가 없다.
1. '기존 데이터 복제', 2. 'Trigger를 통한 신규 데이터 복제' 두 가지만 같은 시점에 명령하면 되었다.
스케줄을 통해 기존 데이터 복제와 Trigger 생성을 동시에 하려고 하였으나...
Trigger는 Schedule을 통한 생성이 불가능했다.

불가피하게 데이터 복제와 Trigger 생성이 한 트랜잭션 내에서 처리가 불가능한 상황이었다.
이로 인해 1번과 2번 사이에서 사용자가 구버전의 테이블에 삽입/수정을 진행하면
Trigger가 생성되기 이전이므로 신규 테이블에 반영되지 않을 것이다.
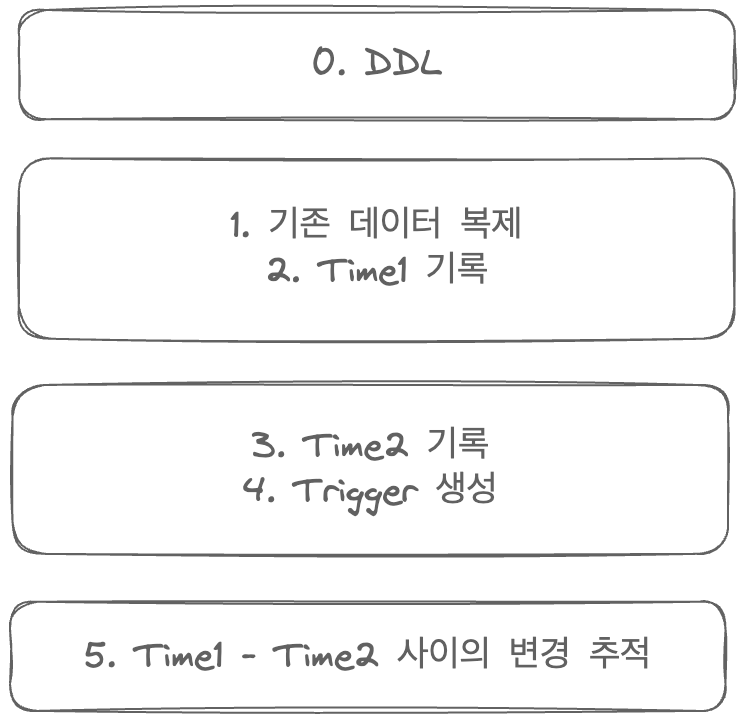
이를 해결하기 위해 데이터 복제가 끝난 시점의 시간과 Trigger를 선언하기 직전의 시간을 기록한다.
마지막에 'last_modified_date'을 참조하여 이 사이에 변경이 있었던 기록을 다시 추적하여 직접 반영하는 스크립트를 추가로 만들었다.
WAS를 통해 DB를 사용할 땐 Locking Read를 사용하므로 복제 시점에 일시적인 성능 저하가 있을 순 있지만 현 서비스 규모에서는 크게 문제 되지 않는다 판단하였고 실제로도 그랬다.
테스트 서버에서 환경을 동일하게 구성하여 수 차례 스크립트들을 순차적으로 실행시키며 점검하였다.
꼬박 하루를 소요했지만 다행히 문제없이 DB의 무중단 마이그레이션을 진행했다.
'하루스터디' 카테고리의 다른 글
| 정적 파일, 웹 서버, DB 스키마까지 무중단 배포 시도하기(1) - 무중단 배포 과정 계획하기 (1) | 2023.10.15 |
|---|---|
| 우리 서버는 어느 정도의 부하를 견딜 수 있을까 - 부하 테스트 계획 & 실행 (1) | 2023.10.10 |
| 밤에 DB와 서버를 안전하게 예약 중단 배포하기 (0) | 2023.09.04 |
| SpringBoot Application과 Grafana 기반의 Metric & Log 모니터링 (4) | 2023.08.13 |
| 언제 JPA를 통해 슈퍼/서브타입을 사용해야 할까? (0) | 2023.07.30 |
- Total
- Today
- Yesterday
- 생성자 주입
- JPA
- Spring
- 함수형 인터페이스
- Java
- 스프링
- GitHub Discussion Template
- java switch case
- RandomPort
- springboottest
- Payload 암호화
- thenComparing
- GitHub Discussion 템플릿
- logback-spring.xml
- multiplebagsfetchexception
- Spring 테스트
- MySQL 이벤트 스케줄
- invokedynamic
- 가변 인수
- MySQL
- JPA JSON
- 람다식
- stubbing
- Fromtail
- comparing
- Spring Boot Monitoring
- 자바
- GitHub Discussion
- 의존성 주입
- Jenkins 예약 배포
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |